
With the increase in computing power and bandwidth of communication channels, the volume of processed data and requirements for processing speed have also increased. Now more and more systems require that data be worked in real time. Apache Kafka is a distributed open source software message broker. Kafka’s goal is to create a horizontally scalable platform for real-time streaming data processing with high bandwidth and low latency.
Another popular solution is the use of microservices architecture to create large-scale applications. It allows developers to divide complex applications into smaller, independent and weakly connected services that interact with each other using simplified protocols. The Kafka broker can also be used as an interaction tool. In this article, we will consider methods that can be used to ensure effective interaction between microservices using Kafka.
Event-driven architecture
Event Driven Architecture (EDA) is an event-driven template that allows microservices to interact with each other using events. In this template, services generate events when certain actions are performed, and other microservices can subscribe to these events and respond accordingly.
As an example, let’s consider a situation when we have one microservice that processes payments and another that sends notifications to customers. When we make a payment, the payment microservice generates an event containing payment information, and the notification microservice subscribed to this event sends a notification to the client.
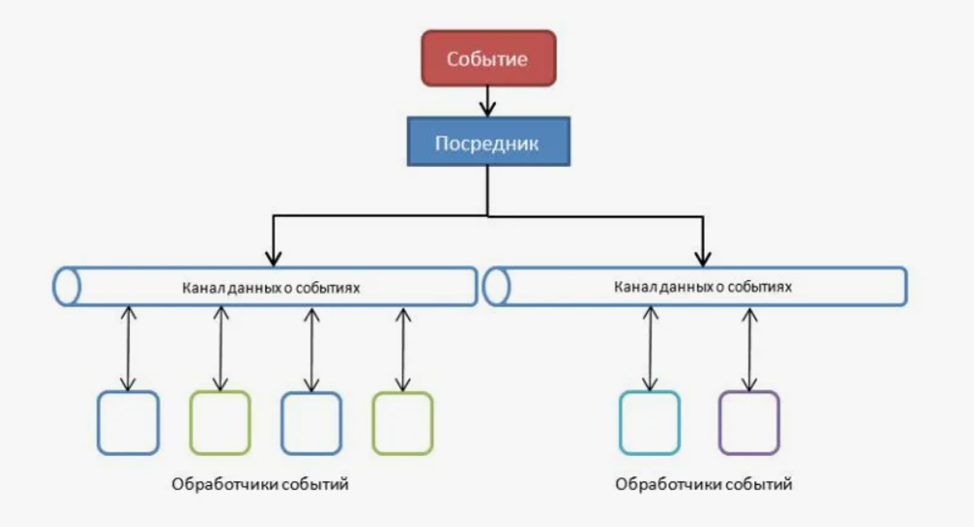
If we talk about the implementation of this logic with the help of Kafka, here we can use topics to implement an event-driven architecture. In this case, each topic can represent a certain event, and services can subscribe to the topics they are interested in.
In the code examples below, we first create the publishers:
from kafka import KafkaProducer
# Kafka broker configuration
bootstrap_servers = 'localhost:9092'
# Create Kafka producer
producer = KafkaProducer(bootstrap_servers=bootstrap_servers)
# Define the topic to produce messages to
topic = 'test_topic'
# Produce a message
message = 'Hello, Kafka Broker!'
producer.send(topic, value=message.encode('utf-8'))
# Wait for the message to be delivered to Kafka
producer.flush()
# Close the producer
producer.close()And in the following fragment we create a consumer:
from kafka import KafkaConsumer
# Kafka broker configuration
bootstrap_servers = 'localhost:9092'
# Create Kafka consumer
consumer = KafkaConsumer(bootstrap_servers=bootstrap_servers)
# Define the topic to consume messages from
topic = 'test_topic'
# Subscribe to the topic
consumer.subscribe(topics=[topic])
# Start consuming messages
for message in consumer:
# Process the consumed message
print(f"Received message: {message.value.decode('utf-8')}")
# Close the consumer
consumer.close()Our information exchange participants interact with each other through the test_topic topic. At the same time, the consumer processes each received message.
Request-response
Another common way microservices interact with each other is the Request-Response template. Here the interaction model can be called more classic, since the microservice simply sends a request to another microservice and waits for a response.
For example, suppose we have a microservice that processes orders, and another microservice that checks the availability of goods in the warehouse, in other words, conducts an inventory. Whenever a customer places an order, the order microservice can send a request to the microservice of inventory to check if the product is available. Then the micro-inventory service can send a response indicating the availability of the goods.
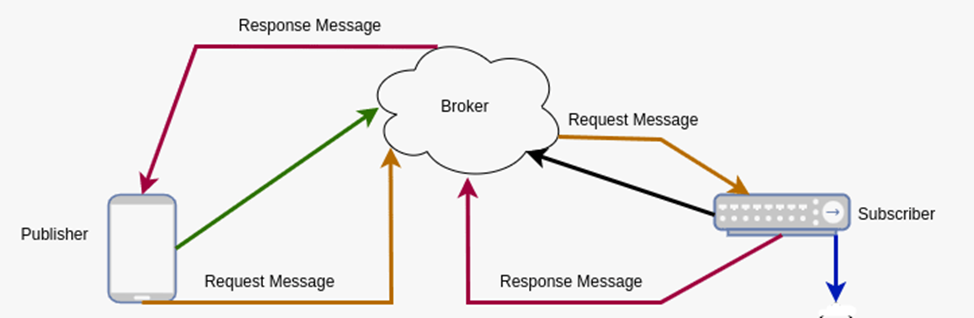
In Kafka, each request can be sent to a specific topic, and the answer can also be sent back to the topic for confirmation.
Command Query Responsibility Segregation
Command Query Responsibility Segregation (CQRS) – division of responsibility for a command query is a template that separates read and write operations in a microservice. In this template, one microservice is responsible for processing commands (write operations), and another microservice is responsible for processing requests (read operations).
For example, let’s assume that we have a microservice that manages customer profiles. Another microservice may be responsible for processing read operations, such as receiving customer information. Recording operations can be performed by another microservice that updates customer information.
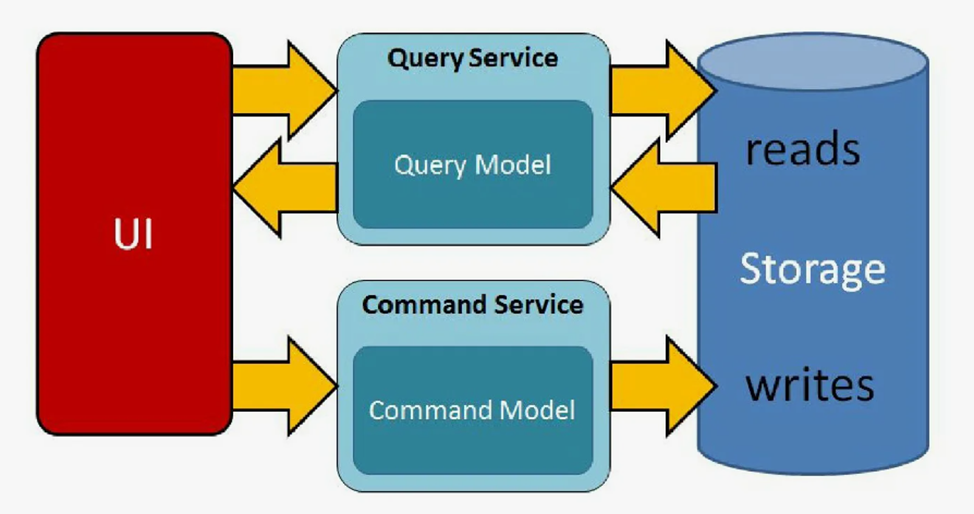
In Kafka, we can use topics to separate read and write operations. Each microservice can publish messages in a certain topic, and other services can subscribe to these topics to receive or update information.
We measure productivity
Next, we will talk about how to measure the performance of the interaction process between microservices using Kafka. For monitoring, Kafka contains several indicators that can be used to assess the performance of the messaging system. First of all, it is the bandwidth, that is, the speed at which Kafka processes messages. It can be measured in messages per second or bytes per second.
Also an important characteristic is the delay, that is, the time required to deliver the message from the producer to the consumer. This value can be measured in milliseconds.
When exchanging messages, it is important to take into account the size of messages sent between microservices. Excessively large messages can affect the performance of the messaging system.
Well, another important indicator is the size of queues, that is, the time interval during which messages are in the topic. Increasing this interval may indicate performance problems.
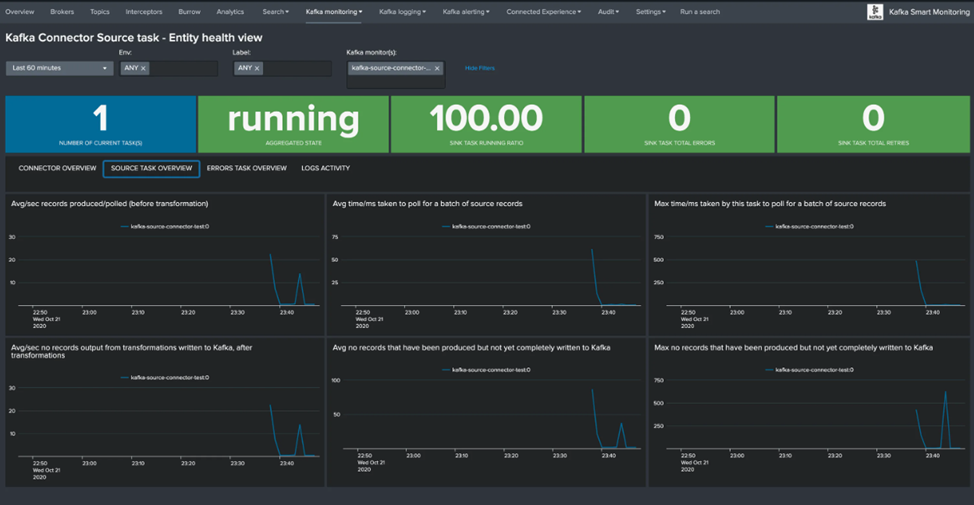
Monitoring these indicators can help identify any performance problems and take appropriate measures to improve interaction between microservices.
We solve problems
Performance problems can be very diverse, and their reason does not always lie in the Kafka software itself. Problems can be with the hardware, communication channels, OS and infrastructure software settings, and many others. However, let’s look at several methods that can be used to improve the performance of interaction between microservices using Kafka.
Here you should start by optimizing the size of messages using data compression can improve the performance of the exchange system. Kafka supports five types of compression: none, gzip, snappy, lz4 and zstd. In general, it is recommended to use lz4 to improve performance. At the same time, the popular gzip is not recommended for use due to high overhead costs. But if you are looking for a compression ratio similar to gzip, but with less CPU overhead, try using zstd. It should be remembered that each unique pipeline or application requires testing to determine the optimal type of compression.
Also an important element of improving productivity is partitioning, which allows Kafka to distribute messages between several brokers and increase the bandwidth of the messaging system. Separation can be based on various criteria, such as message type, time or customer ID. Scaling of consumers can improve message processing and increase the bandwidth of the messaging system. Kafka allows you to scale consumers horizontally, adding more consumer instances.
Finally, flexible configuration of Kafka configuration parameters, such as packet size, buffer size and replication factor, can improve the performance of the messaging system.
Conclusion
Apache Kafka is a fairly powerful tool that allows you to solve various tasks. In this article, we have considered the main templates for working with microservices and some performance monitoring issues.



About The Author: Yotec Team
More posts by Yotec Team