
Software extraction of data, such as text and images, from Word documents can greatly facilitate the automation of document processing tasks, simplify the analysis and integration of this data into other systems.
In this post, I will tell you how to extract text, tables and images from a Word document using the Python library designed to work with Word files.
- Extracting text from a Word document
- Extracting tables from a Word document
- Extracting images from a Word document
Python library for reading Word documents
Spire.Doc for Python is a library that simplifies work with Microsoft Office Word documents. It allows you to programmatically read, write and manipulate Word documents, facilitating the automation of document-related tasks.
You can install the library from PyPI using the following command.
pip install Spire.DocExtracting text from a Word document
In Spire.Doc, you can load a Word file using the Document.LoadFromFile() method, specifying the file path as a parameter. After that, you can get the text of the document using the Document.GetText() method.
from spire.doc import *
from spire.doc.common import *
# Создайте объект документа
doc = Document()
# Загрузите файл Word
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Input.docx")
# Получите текст из всего документа
text = doc.GetText()
# Сохраните текст в текстовый файл
with open("C:\\Users\\Administrator\\Desktop\\ExtractedText.txt", "w", encoding="utf-8") as text_file:
text_file.write(text)
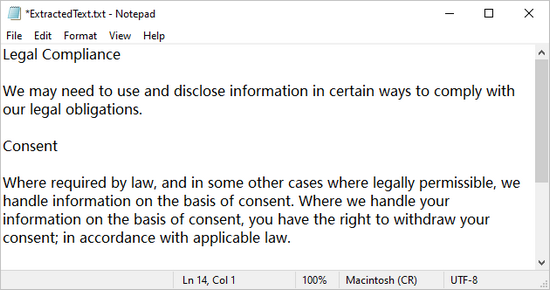
Output:
Extracting tables from a Word document
With Spire.Doc, access to tables in the Word document section is very easy. You can use the Section.Tables property to get a collection of all tables present in this section. Having received this collection, you can find a specific table by its index or other identifying properties.
Having received a specific table, you can interact with its cells by referring to the Rows property, which provides a collection of all rows in the table. Each line contains several cells, which can be accessed through the Cells property.
To extract text content from each cell, you use the TableCell object. By Calling TableCell.Paragraphs.get_Item(). Text, you can get the text of each paragraph in a cell.
from spire.doc import *
from spire.doc.common import *
# Создайте объект документа
doc = Document()
# Загрузите документ Word
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\input.docx")
# Переберите секции
for i in range(doc.Sections.Count):
# Получите конкретную секцию
section = doc.Sections.get_Item(i)
# Получите таблицы из секции
tables = section.Tables
# Переберите таблицы
for j in range(0, tables.Count):
# Получите определённую таблицу
table = tables.get_Item(j)
# Объявите переменную для хранения данных таблицы
tableData = ""
# Переберите строки таблицы
for m in range(0, table.Rows.Count):
# Переберите ячейки строки
for n in range(0, table.Rows.get_Item(m).Cells.Count):
# Получите ячейку
cell = table.Rows.get_Item(m).Cells.get_Item(n)
# Получите текст в ячейке
cellText = ""
for para in range(cell.Paragraphs.Count):
paragraphText = cell.Paragraphs.get_Item(para).Text
cellText += (paragraphText + " ")
# Добавьте текст к строке
tableData += cellText
# Добавьте новую строку
tableData += "\n"
# Сохраните данные таблицы в текстовый файл
with open(f"output/WordTable_{i+1}_{j+1}.txt", "w", encoding="utf-8") as f:
f.write(tableData)Output:

Extracting images from a Word document
To extract an image from a Word document, you first need to go through the child objects contained in the document. Each child object represents different elements of the document, such as text or images.
During this iteration, it is necessary to check whether any of the child objects belongs to the DocPicture type, which specifically represents images in the document. If the child object is really DocPicture, you can access the image data using the ImageBytes property of the DocPicture object. This property provides raw byte data of the image, which can then be saved to a file.
You can specify the desired file format (e.g. PNG, JPEG) and the path you want to save the image, which will allow you to successfully extract and save images for future use.
import queue
from spire.doc import *
from spire.doc.common import *
# Создайте объект документа
doc = Document()
# Загрузите файл Word
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\input.docx")
# Создайте объект очереди
nodes = queue.Queue()
nodes.put(doc)
# Создайте список
images = []
while nodes.qsize() > 0:
node = nodes.get()
# Переберите дочерние объекты в документе
for i in range(node.ChildObjects.Count):
child = node.ChildObjects.get_Item(i)
# Определите, является ли дочерний объект изображением
if child.DocumentObjectType == DocumentObjectType.Picture:
picture = child if isinstance(child, DocPicture) else None
dataBytes = picture.ImageBytes
# Добавьте данные изображения в список
images.append(dataBytes)
elif isinstance(child, ICompositeObject):
nodes.put(child if isinstance(child, ICompositeObject) else None)
# Переберите изображения в списке
for i, item in enumerate(images):
fileName = "Image-{}.png".format(i)
with open("ExtractedImages/"+fileName, 'wb') as imageFile:
# Запишите изображение в указанное место
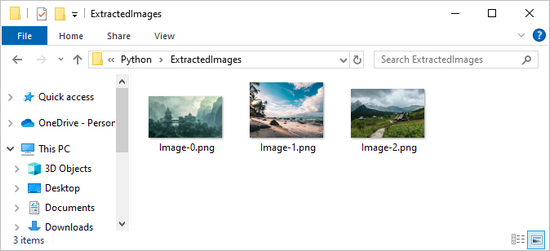
imageFile.write(item)Output:
Need to build a custom Python tool for document processing or data extraction? Our team specializes in Python custom development for automation and integration.




About The Author: Yotec Team
More posts by Yotec Team